동일 업종 공장 내 위험의 상대평가 서비스 소개
글 최명영 화재보험협회 위험관리지원센터 과장, 공학박사
1. 머리말
화재 발생을 정확하게 예측하는 것은 매우 어렵다. 하지만 이것은 인간의 생명과 재산을 보호하는 데 있어 매우 중요하여 많은 위험관리 기관이 이에 대한 연구를 수행하고 있다. 화재보험협회는 지난 1973년 제정된 "화재로 인한 재해보상과 보험 가입에 관한 법률"에 따라 전국의 중대형 건물에 대한 의무 보험이 도입되며, 화재예방 및 보험기술 발전을 위해 설립된 위험관리 전문기관이다. 화재보험협회 위험관리지원센터에서도 협회의 설립 취지에 맞게 화재로 인한 피해를 경감하기 위해 화재 위험 예측 및 평가 방법을 연구하고 있다. 화재보험협회는 설립 이후 특수건물에 대한 안전점검을 수행하고 있다.
안전점검이란 건축물의 방재시설 및 생산 공장에서 작업공정 등에 내재된 화재발생요인과 각종 위험요소를 사전에 발견하여 이를 제거하도록 적극 권장하고, 재해가 발생하였을 경우에도 피해를 최소화하기 위한 방재기술 및 보험대책을 제시하는 화재예방활동을 말한다. 화재보험협회는 안전점검을 실시한 후 위험을 평가하여 이 결과물을 요약한 후 손해보험회사로 전달하여 특수건물의 화재보험에 적용되도록 한다.
위험을 평가하는 기법에는 여러 가지 방법이 있는데 여기서는 언더라이팅 자료 조회시스템1)(UCIS, Underwriting Comprehensive Information System)를 통해 손해보험회사에 2020년 12월 부터 서비스하고 있는 안전점검 및 사고 데이터에 기반한 동일 업종 내 위험의 상대평가 서비스에 대해 소개하고자 한다.
2. 서베이 및 사고DB에 기반한 신규 지수
가. 연구 배경
화재는 오랫동안 인간의 생명과 재산에 치명적인 결과를 초래하였으며, 그에 따라 인간은 화재에 대처하기 위해 다양한 노력을 기울여 왔다. 그 중 하나는 화재의 발생 가능성을 예측하는 것이다. 하지만 실제로 화재 발생을 예측하는 것은 화재에 영향을 미치는 변수가 많고 전체 데이터에서 화재 발생 건수가 매우 적어 매우 어렵다. 이러한 난관을 극복하기 위해 로지스틱 회귀(logistic regression)2), 서포트 벡터 머신(support vector machine, SVM)3), 랜덤 포레스트(random forest)4), 부스팅(boosting)5)등과 같은 다양한 머신러닝(machine learning) 알고리즘을 활용하여 산불이나 건축물 화재를 예측하기 위한 연구도 활발하게 진행되고 있다. 미국의 애틀랜타 소방서가 주축으로 수행한 연구에서는 화재 위험을 예측하고 화재 검사의 우선 순위를 정하기 위해 서포트 벡터 머신과 랜덤 포레스트 기법을 활용하여 'Firebird'를 개발하였다. 다양한 연구에도 불구하고, 화재 예측 모델의 정확도가 여전히 매우 높은 수준은 아닌데, 이러한 사실이 정확한 화재 발생 예측이 어렵다는 것을 반증하고 있다.
최근 많이 활용되고 있는 머신러닝 기법 외에도 이와 전통적인 방법에 기반한 연구도 계속 수행되어 왔는데, Watts 는 화재 위험을 예측하는 또 다른 새로운 방법으로 화재 안전을 위한 화재 전문가의 지식과 경험을 바탕으로 한 휴리스틱6) 모델에 기반한 화재위험지수가 활용되었다.
안전점검 및 사고 데이터에 기반한 동일 업종 내 위험의 상대평가 서비스는 다양한 방법을 통해 화재 위험을 평가하는 방법을 연구하던 중 점검 및 사고 데이터에 기반하여 최적화된 배점을 부여하는 방식을 적용하였을 때 화재의 빈도 및 심도 예측 정확도가 향상되는 것이 확인되어, 이에 대한 소개를 하고자 한다.
나. 모델링
신규지수는 기존에 협회에서 제공하고 있는 화재위험도지수와는 달리 화재의 빈도와 심도의 2차원 정보를 제공하고 있으며, 위험도지수의 각 구성요소 배점을 달리하며, 화재 빈도 및 심도 결과에 최적화된 배점을 도출하였다. 또한 이 기법은 과거 데이터를 입력변수로 활용하여 종속변수를 예측하는 것으로 모형 구축용 데이터와 성능평가용 데이터의 구분이 필수적이다. 2011~2017년 안전점검 및 화재 데이터를 활용하여 이에 최적화하여 모형을 구축한 후, 2018~2019년의 신규 지수를 산출하였으며 이를 실제 사고 결과값과 비교하였다.
■ 빈도 최적화 구성요소 배점 : KFRI 구성요소 중 화재 빈도와 관련이 높은 항목만 선별하여 계산 후 화재 발생물건의 지수 평균값과 화재 미발생물건의 지수 평균값의 차이를 가장 커지게 하는 구성요소의 배점 도출
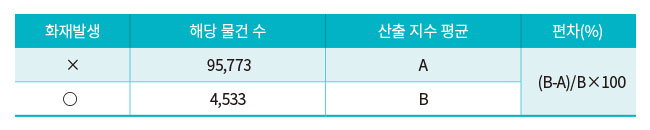
■ 심도 최적화 구성요소 배점 : KFRI 구성요소 중 화재 심도와 관련이 높은 항목만 선별하여 계산 후 화재가 발생한 물건의 지수 중 상·하위 30% 물건의 화재심도(재산피해합계/면적합계×100) 평균값의 차이를 가장 커지게 하는 구성요소의 배점 도출
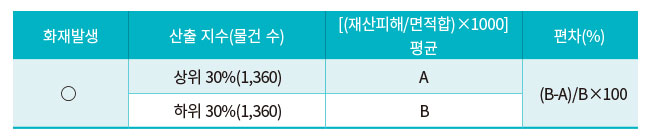
다. 성능 평가
구축된 모형의 예측정확도는 성능 평가 시 데이터 마이닝 분야에서 활용되는 Lift Value를 사용하였다. 화재 빈도를 예로 들면, Baseline lift는 전체 물건 수 중 화재가 발생한 물건 수인 평균 화재 발생률을 나타내고, Top 10% lift는 신규 지수를 내림차순으로 정렬하여 지수의 상위 10% 물건의 화재 발생률을 나타낸다. Lift Value가 클수록 상대적으로 위험한 상위 10% 물건의 화재 발생률이 평균 화재 발생률 대비 높은 것으로 모델의 예측 성능이 우수하다고 할 수 있다.
■ 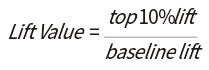
- Top 10% lift : 각 지수(모형)의 값에 의해 정렬된 데이터 상위 10%에 포함된 화재 건수 비율 또는 심도 지수
- Baseline lift : 모형 구축 전 전체 데이터에 포함된 화재 건수에 대한 비율 또는 심도 지수 평균
Lift Value가 클수록 상대적으로 위험한 상위 10% 물건의 화재 발생률이 평균 화재 발생률 대비 높은 것으로 모델의 예측 성능이 우수하다고 할 수 있다.
■ 배점 최적화 전·후 생성된 KFRI 지수의 Lift Value 비교
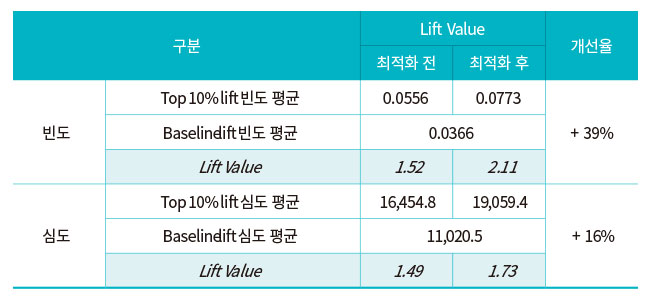
2011~2017년 안전점검 및 화재 데이터를 활용하여 이에 최적화하여 모형을 구축한 후, 2018~2019년의 신규 지수를 산출하여 성능을 예측한 결과 화재의 빈도 및 심도는 기존 대비 각각 39% 및 16% 개선된 것을 확인할 수 있었다. 위험도지수 개선 연구를 통해 이 방법론의 유효성이 확인되었으나 이에 대한 대외 공신력을 높이고, 전문가 그룹을 통한 감수를 거치기 위해 SCI급 논문에 투고 및 게재되었다.[1] 이 방법론의 성능이 검증되어 2011~2019년의 9년치 데이터에 최적화하여 2020년 말 UCIS 4.0에 최초 서비스를 제공하였으며, 2021년 2월 중 2011~2020년의 10년치 데이터7)에 최적화한 후 서비스를 제공 중에 있다.
라. 서비스 설명
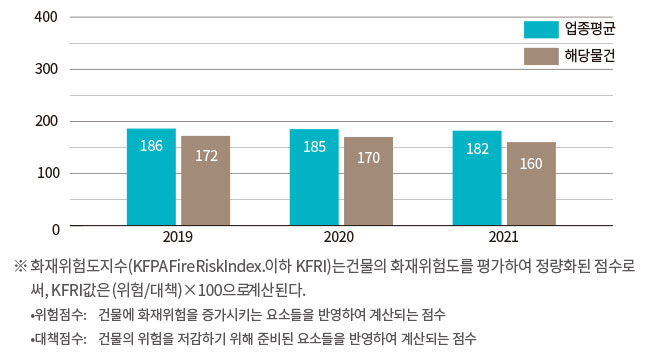
UCIS 3.0에서도 최근 3년간 화재위험도지수 변화 추이 정보를 아래 그림과 같이 표출하고 있었다. 화재위험도지수는 화재보험요율서에서 활용되고 있는 정보로 건물의 화재위험도를 평가하여 정량화된 지수로서 화재의 빈도와 심도 개념이 복합적으로 녹여져 있다. 또한 기존의 서비스는 업종평균 화재위험도지수 대비 해당물건의 화재위험도지수를 비교 표출하고 있어 개략적인 상대평가가 가능하다.
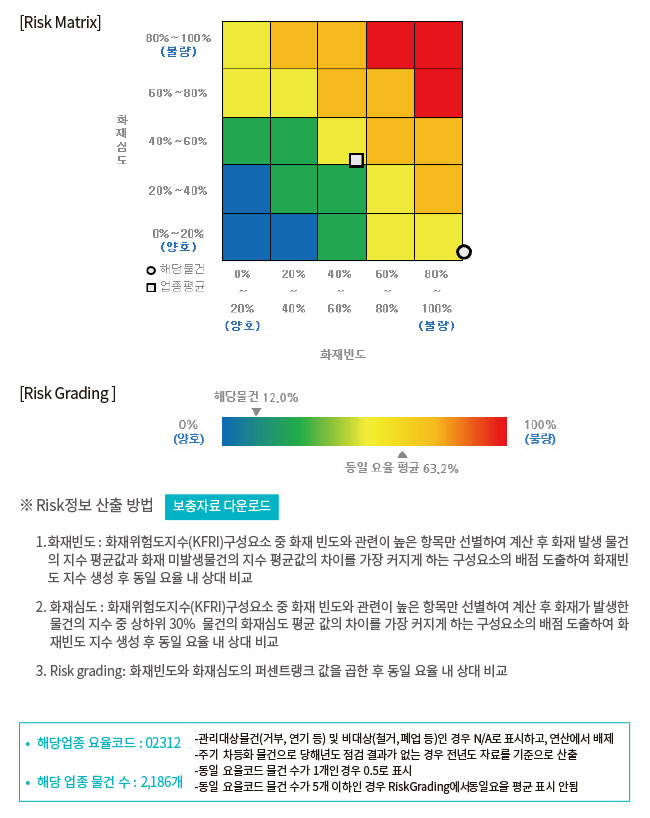
UCIS 4.0에서 추가된 아래 그림의 “서베이 및 사고DB에 기반한 동일 업종내 위험의 상대평가” 에서는 건물의 위험을 화재의 빈도와 심도로 구분하여 리스크 매트릭스 형태로 표출하고 있다. 실제 사고에 최적화한 빈도와 심도 지수를 동일 업종 내에서 그 크기를 비교하여 백분위 순위로 나타내어 Risk matrix에 표시한다. 동일 업종 내 화재의 빈도 및 심도지수 크기를 비교하여 백분위 순위로 나타낸 후 그 값을 곱하여 Risk Grading에 표출해준다. 해당 물건의 정보뿐만 아니라 동일 요율의 평균값도 비교하여 위험의 상대 비교가 가능한 정보를 제공하고 있다.
[3년간 화재위험도지수 변화 추이]
[서베이 및 사고 DB에 기반한 동일 업종내 위험의 상대평가]
마. 한계 및 주의사항
다년간의 데이터를 수차례 최적화하여 빈도 및 심도 예측정확도를 분석해본 결과, 신규 빈도 지수는 샘플 수가 충분히 많아서 예측정확도가 안정적으로 향상됨을 확인할 수 있었다. 하지만 심도 지수는 화재가 발생한 물건을 입력 변수로 활용하여 상대적으로 샘플 수가 매우 적어 구성요소의 배점 변동 폭이 크고, 예측정확도가 불안정하다. 또한 이 기법은 과거 사고 데이터에 기반하여 빈도와 심도 리스크를 예측하고 있는데, 화재 빈도의 경우 구성요소와 화재와의 상관관계 분석을 수행해보면 면적과의 상관계수가 상대적으로 높다. 이에 따라 공장 물건에 대해 동일 업종 내 빈도 리스크를 상대 비교할 때 면적 차이가 크다면 대형 공장이 더 열악한 평가를 받을 확률이 높으므로, 이를 감안하여 참조해야 한다.
3. 맺음말
화재는 매우 복잡한 요소에 의해 발생되므로 이를 예측하는 것이 쉽지 않다. 화재를 예측하기 위한 시도는 오래 전부터 있어 왔는데, 최근 들어서는 미국방화협회(NFPA), 뉴욕 소방국(FDNY), 애틀랜타 소방국에서 머신러닝 기법을 도입하여 리스크를 관리하려는 움직임을 보이고 있다. 이러한 분석 모델 구축 시 가장 중요하다고 할 수 있는 것이 양질의 분석용 데이터를 구하는 것인데, 데이터 분석에 있어 통용되고 있는 “Garbage in, Garbage out(GIGO, 쓰레기가 들어가면 쓰레기가 나온다)”에서도 알 수 있듯이 입력 데이터의 품질이 매우 중요하다.
협회에서는 수십 년간 축적된 점검 노하우 및 점검 품질 관리를 통해 양질의 균질화된 정보를 도출하기 위해 지속적으로 노력하고 있으며, 이러한 정보를 활용하여 건물의 화재 위험을 예측하기 위한 다양한 연구를 수행하고 있다. 현재 서베이 및 사고DB에 기반한 동일 업종 내 위험의 상대평가 서비스는 공장물건에 한하여 제공되고 있지만, 이 서비스가 시장에서 널리 활용된다면 공장 물건 이외의 특수건물에도 제공될 수 있을 뿐 아니라, 더 나아가 공장 물건 중 샘플이 충분한 특정 업종에 지수를 최적화하여 지수의 예측 정확도를 높이는 것도 가능할 것이다.
출처
[2] Rishickesh, R.; Shahina, A.; Nayeemulla Khan, A. Predicting Forest Fires using Supervised and Ensemble Machine Learning Algorithms. Int. J. Recent Technol. Eng. 2019, 8, 3697–3705.
[3] Rishickesh, R.; Shahina, A.; Nayeemulla Khan, A. Predicting Forest Fires using Supervised and Ensemble Machine Learning Algorithms. Int. J. Recent Technol. Eng. 2019, 8, 3697–3705.
[4] Madaio, M.; Chen, S.T.; Haimson, O.L.; Zhang, W.; Cheng, X.; Hinds-Aldrich, M.; Chau, D.H.; Dilkina, B. Firebird: Predicting Fire Risk and Prioritizing Fire Inspections in Atlanta. In Proceedings of the 22nd ACM SIGKDD Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 185–194.
[5] Nikolopoulos, E.I.; Destro, E.; Bhuiyan, M.A.E.; Borga, M.; Anagnostou, E.N. Evaluation of predictive models for post-fire debris flow occurrence in the western United States. Nat. Hazards Earth Syst. Sci. 2018, 18, 2331–2343.
[6] Watts, J.M. Fire Risk Indexing. SFPE Handbook Fire Protection Eng. 2016, 3, 3158–3182.
1) https://ucis.kfpa.or.kr/
2) 영국의 통계학자인 D. R. Cox가 1958년에 제안한 확률 모델로서 독립 변수의 선형 결합을 이용하여 사건의 발생 가능성을 예측하는데 사용되는 통계 기법이다. 로지스틱 회귀는 선형 회귀 분석과는 다르게 종속 변수가 범주형 데이터를 대상으로 하며 입력 데이터가 주어졌을 때 해당 데이터의 결과가 특정 분류로 나뉘기 때문에 일종의 분류 (classification) 기법으로도 볼 수 있다. (출처: 위키백과)
3) 기계 학습의 분야 중 하나로 패턴 인식, 자료 분석을 위한 지도 학습 모델이며, 주로 분류와 회귀 분석을 위해 사용한다. 두 카테고리 중 어느 하나에 속한 데이터의 집합이 주어졌을 때, SVM 알고리즘은 주어진 데이터 집합을 바탕으로 하여 새로운 데이터가 어느 카테고리에 속할지 판단하는 비확률적 이진 선형 분류 모델을 만든다. 만들어진 분류 모델은 데이터가 사상된 공간에서 경계로 표현되는데 SVM 알고리즘은 그 중 가장 큰 폭을 가진 경계를 찾는 알고리즘이다. (출처: 위키백과)
4) 기계 학습에서의 랜덤 포레스트(영어: random forest)는 분류, 회귀 분석 등에 사용되는 앙상블 학습 방법(학습 알고리즘을 따로 쓰는 경우에 비해 더 좋은 예측 성능을 얻기 위해 다수의 학습 알고리즘을 사용하는 방법)의 일종으로, 훈련 과정에서 구성한 다수의 결정 트리로부터 부류(분류) 또는 평균 예측치(회귀 분석)를 출력함으로써 동작한다. (출처: 위키백과)
5) 성능이 약한 학습기(weak learner)를 여러 개 연결하여 순차적으로 학습함으로써 강한 학습기(strong learner)를 만드는 앙상블 학습기법 (출처: IT위키)
6) 휴리스틱(heuristics) 또는 발견법(發見法)이란 불충분한 시간이나 정보로 인하여 합리적인 판단을 할 수 없거나, 체계적이면서 합리적인 판단이 굳이 필요하지 않은 상황에서 사람들이 빠르게 사용할 수 있게 보다 용이하게 구성된 간편 추론의 방법이다. (출처: 위키백과)
7) 빈도 분석 데이터: ‘11~‘20년 공장물건 154,216개, 심도 분석 데이터: ‘11~‘20년 공장 중 화재발생 물건 6,419개